Self-Attention와 Multi-Head Attention
Self- Attention
Attention
자연어 처리(NLP) 분야에서 'Attention'은 혁신적인 발전을 가져왔습니다. 기존의 Seq2Seq 모델에서의 한계를 극복하며 더욱 정밀하고 정교한 번역이 가능해졌습니다. 이번에는 Attention 메커니즘의 기
gogomake.tistory.com
저번 포스팅에서 Attention의 개념과 계산하는 과정을 설명했습니다. 이번 포스팅에서는 이어서 Query, Key, Value를 설명하고 Self-Attention에 대해 설명하겠습니다. 만약 Attention 개념이 생소하다면, 위 포스팅을 다시 참고하시길 바랍니다.
Query, Key, Value

이전에 설명한 Attention의 과정입니다. 여기서 Query, Key 그리고 Value를 표시하면 다음과 같습니다.

Query, Key, Value를 이용해서 계산한 과정은 간단하게 3단계로 요약할 수 있습니다.
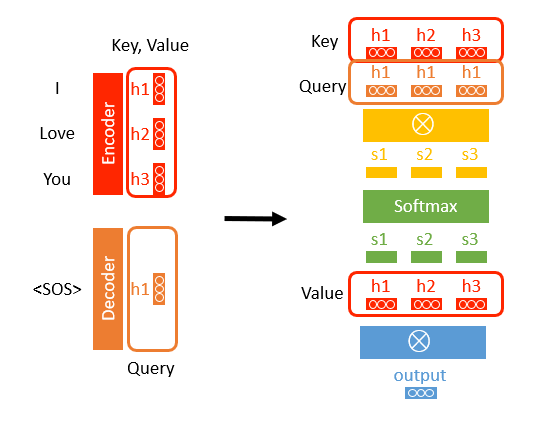
- Query와 Key를 내적해서 Attention Score얻는다.
- Attention Score를 Softmax를 통해 Softmax Score를 얻는다.
- Softmax Score와 Value를 내적해서 Output을 얻는다.
이를 수식으로 표현하면 다음과 같습니다.
$\mathbf{softmax}(QK^t)V = O$
Self-Attention
이처럼 Attention은 Query, Key, Value를 이용해서 Output을 출력합니다. 여기서 Query, Key, Value가 같은 벡터의 '출처'라면, Self-Attention이 됩니다.

여기서 조금 더 심플하게 그려보면 다음과 같습니다.

잠시만요? 여기서 Scale이란 게 추가되었습니다. Scale은 Q와 K의 내적한 결과에 Q와 K의 길이 나눕니다. 그럼 Scale은 왜 추가했을까요?
Q와 K를 내적 할 때 분산이 증가하는 문제가 발생할 수 있습니다. 분산이 증가하면 Softmax에서 특정값이 유난히 커질 문제가 발생합니다. 특정값이 유난히 커지면 편중된 분포를 갖게 됩니다. 그럼, Output은 특정값만 계속 출력되는 문제점이 발생하게 됩니다. 이를 해결하기 위해 Q와 K의 길이만큼 나눠주면 분산이 줄어듭니다. 이를 식으로 표현하면 다음과 같습니다.
$\mathbf{softmax}(\frac{QK^t}{\sqrt{d_k}})V$
Multi-Head Attention
Multi-Head Attention은 간단합니다. Self-Attentnion을 여러 개 사용한 것이 Multi-Head Attention입니다.

여러개 Self-Attentnion에서 얻은 Output을 Concat해서 Linear로 전달해주면, Multi-Head Attention이 완성됩니다.
마무리
지금까지 Attention의 주요 개념과 Self-Attention 및 Multi-Head Attention에 대해 알아보았습니다. 이러한 개념들은 자연어 처리에서 매우 중요한 역할을 합니다. 이 포스팅을 통해 Attention의 핵심을 파악하셨기를 바랍니다. 궁금한 점이나 더 알고 싶은 내용이 있다면 언제든지 댓글로 남겨주세요.