Attention
자연어 처리(NLP) 분야에서 'Attention'은 혁신적인 발전을 가져왔습니다. 기존의 Seq2Seq 모델에서의 한계를 극복하며 더욱 정밀하고 정교한 번역이 가능해졌습니다.
이번에는 Attention 메커니즘의 기본 원리와 그 작동 방식에 대해 상세히 알아보도록 하겠습니다.
Attention
Attention은 Seq2Seq의 문제점을 극복하기 위해 나타났습니다.
Seq2Seq는 NLP에서 널리 사용하는 구조로, 입력 시퀀스를 Encoder에 전달하고, 그 결과를 Decoder로 출력하여 변환된 시퀀스를 얻는 구조입니다.

Seq2Seq의 주요 문제점은 고정된 크기의 Latent vector가 긴 입력정보를 충분히 담지 못한다는 것입니다. 즉, 정보의 손실이 발생할 수 있습니다.
이를 해결하기 위해 Attention이 나왔습니다. Attention은 입력 시퀀스 중 필요한 부분만 집중해서 그 정보만 가져오는 것이 주요 목적입니다.
Attention의 전반적인 과정은 다음과 같습니다.

- Encoder를 통해 각 입력 시퀀스에 대한 hidden(embedding)을 얻습니다.
- Decoder의 매 스텝에서 hidden(embedding)을 얻습니다.
- Encoder와 Decoder의 hidden(embedding)간에 내적해서 score를 얻습니다.
- score를 softmax를 사용해서 softmax score를 얻습니다.
- softmax score와 Encoder hidden(embedding)를 곱한 후, 합산하여 context vector를 얻습니다.
- context vector와 Decoder hidden(embedding)을 concat합니다.
- concat한 벡터를 FNN(Feedforward Neural Network)로 전달하여 출력을 얻습니다.
예시를 통해 위 과정을 설명하겠습니다. 우리는 영어를 한국어로 번역하는 번역기 모델을 만들려고 합니다.
1. Encoder과정
Encoder은 번역기 모델의 입력 부분에 해당합니다. Encoder에는 RNN(RNN, LSTM)으로 구성되어 있습니다. 그래서 입력값을 주면 hidden을 통해 출력값을 얻을 수 있습니다.

'I Love You'를 Encoder에 입력하면, h1, h2, h3를 얻을 수 있습니다.
2. Decoder과정
이전의 기본적인 Seq2Seq 번역기 모델에서는 Decoder가 Encoder의 마지막 hidden state를 사용하여 바로 번역 문장을 생성했습니다. 하지만, Attention을 사용하면 출력하기 전, Attention의 도움을 받고 문장을 생성합니다.

먼저, Decoder에 '<SOS>'를 입력값으로 전달하면 h1을 얻을 수 있습니다.
3. Attention과정 - score 얻기
앞서 설명했듯이, Attention의 주된 목표는 '입력 시퀀스 중 필요한 부분만 집중해서 그 정보만 가져오는 것'입니다. 이를 위해서는 입력 시퀀스의 각 부분과 현재 Decoder의 상태가 얼마나 관련이 있는지를 알아내는 점수(score)를 계산하는 과정이 필요합니다. 이 점수를 바탕으로 어느 부분에 집중할 것인지를 결정합니다. 이러한 점수 계산과 결정 과정이 Attention의 핵심입니다.
score 계산은 Encoder와 Decoder의 hidden(embedding)간의 관계를 나타내는 값입니다. 관계의 유사도를 나타내는 내적을 이용해서 각각 hidden을 내적합니다. 즉, 내적 값이 큰 경우 Decoder와 해당 Encoder의 hidden 간에 높은 관련성이 있다는 것을 의미하며, 반대로 내적 값이 작을 경우 낮은 관련성을 가진다고 볼 수 있습니다.

h1, h2, h3를 h1과 내적해서 score인 s1, s2, s3를 얻습니다.
4. Attention과정 - softmax score 얻기
이번에는 앞에서 얻은 score를 softmax를 통해 softmax score를 얻는 과정입니다. 그럼, score의 값이 0과 1 사이의 값을 갖게 되고, 모든 값들의 합은 1이 됩니다. 이는 attention의 가중치를 나타내게 됩니다.
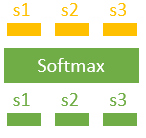
s1, s2, s3을 softmax를 구하면 s1, s2, s3을 얻을 수 있습니다. 각각의 s는 0과 1 사이 값을 갖습니다. s1, s2 그리고 s3의 합은 1입니다.
5. Attention과정 - context vector 얻기
이전까지 과정은 Attention에서 필요한 부분이 무엇인지 파악하는 과정이라면, 이번 과정은 필요한 부분을 추출하는 과정입니다. softmax score를 Encoder의 hidden(embedding)과 곱하면 hidden(embedding)에서 관련성이 높은 부분은 강조되고, 관련성이 낮은 부분은 줄어들게 됩니다. 이렇게 각 입력 부분을 가중치로 조절한 후, 이를 합쳐서 하나의 벡터, 즉 context vector를 생성합니다.

s1, s2, s3과 h1, h2, h3을 각각 곱합니다. 그럼 s1 x h1, s2 x h2, s3 x h3을 얻을 수 있습니다. 그럼 관련성이 높은 부분은 강조되고, 관련성이 낮은 부분은 줄어들게 됩니다. 이후에는 모두 더해서 s1 x h1 + s2 x h2 + s3 x h3 하나의 context vector를 만듭니다. 자! 이렇게 해서필요한 부분을 추출했습니다.
6. Attention과정 - concat 하기
Attention의 마지막 단계입니다. Decoder의 hidden(embedding)과 context vector를 하나로 연결해 주는 concat을 사용합니다. 이렇게 결합된 벡터는 번역의 정확도를 높일 수 있습니다.

h1와 context vector를 하나로 concat 합니다.
7. FNN(Feedforward Neural Network)으로 출력하기
드디어 번역기 모델의 마지막 과정입니다. Attention 과정을 통해 얻은 값을 이용해서 FNN으로 전달하면 번역된 결과를 얻을 수 있습니다.

concat을 FNN으로 전달하면 번역기의 출력인 '나는'을 얻을 수 있습니다.
8. 반복 과정
번역기의 출력인 '나는'은 이제 Decoder의 입력이 됩니다. 이후 과정은 위 과정을 반복합니다.

FNN의 출력이 문장의 끝을 알리는 <EOS>가 될 때까지 반복합니다.

마무리
지금까지 Attention과 그 과정을 상세히 살펴보았습니다. Attention은 딥러닝 기반의 번역기 모델에서 큰 도약을 이루게 한 핵심 기술 중 하나입니다. 이를 통해 모델은 입력 시퀀스의 특정 부분에 집중하여 더욱 정확하고 자연스러운 번역을 수행할 수 있게 되었습니다.
이 글을 읽으시면서, 새로운 지식을 얻었기를 바랍니다. 질문이 있다면 언제든지 댓글로 남겨주시기 바랍니다.